
Eine ausführliche Abhandlung zu dieser Frage liefert Bruno Vollmerts Buch Das Molekül und das Leben – Vom makromolekularen Ursprung des Lebens und der Arten: Was Darwin nicht wissen konnte und Darwinisten nicht wissen wollen. Hier folgt eine knappe Zusammenfassung eines Teils der Fakten:
- Voraussetzungen für das Leben
- Das Ergebnis der Miller-Experimente oder Was nicht im Biologiebuch steht
- Wahrscheinlichkeiten
- Fazit
- Anmerkung 1: Treffen die Polykondensationsgesetze auf die Entstehung des Lebens zu?
- Anmerkung 2: Anzahl Wassermoleküle in den Weltmeeren
- Anmerkung 3: Grundsätzliches zur Protein-Codierung in der DNS
Voraussetzungen für das Leben
Die Grundvoraussetzung für das an Materie gebundene Leben sind Makromoleküle. Die DNS wäre so ein Makromolekül, außerdem jedes Protein. Damit sich ein Lebewesen reproduzieren kann, muss es einen Bauplan (typischerweise DNS) beinhalten, der dem Lebewesen selbst entspricht. Es müssten also bei der zufälligen Entstehung eines ersten Lebewesens Makromoleküle in großer Menge entstehen, die zueinander passen und interagieren, sowie dem Zerfall widerstehen. Wir erhalten eine Kette von Bedingungen:
- Wir benötigen einen Bauplan mit allen Informationen zur Reproduktion des Lebewesens.
- Kann die dafür notwendige Information von selbst entstehen?
- Dieser Bauplan ist in einem Makromolekül (typischerweise DNS) gespeichert.
- Kann ein Makromolekül (d.h. eine Kette von bifunktionellen Einzelmolekülen) von selbst entstehen?
- Konkret auf eine DNS bezogen: Zum Aufbau einer DNS müssten Nukleoside zufällig entstehen.
- Entstehen Nukleoside zufällig?
Betrachten wir diese Kette von Voraussetzungen von hinten, müssten wir somit folgendes herausfinden:
- Entstehen Nukleoside zufällig?
- Wenn nicht, kann logischerweise eine DNS gar nicht erst entstehen. Falls ja, folgt der nächste Schritt:
- Können sich Nukleotide zu einer DNS zusammenketten (Nukleotide stehen hier stellvertretend für bifunktionelle Moleküle und DNS für ein informationstragendes Makromolekül)?
- Wenn nicht, kann Leben nicht zufällig entstehen, da kein Bauplan des Lebens entstehen kann. Wenn ja, folgt der nächste Schritt:
- Kann sich Information in einer DNS zufällig bilden? Zu den zu entstehenden Informationen zählen neben dem Bauplan unter anderem folgende Funktionen:
- Eine Kopierfunktion zur Erstellung eines Duplikats.
- Alle notwendigen Stoffwechselfunktionen zur Energiegewinnung und -nutzung.
- Eine Übersetzungsfunktion, die den genetischen Code in Handlung (bei codierter Funktion (Software)) bzw. in Proteine (bei codierter Bauanleitung (Hardware)) umsetzt.
- Reparaturfunktionen, durch die Funktionalität bzw. Struktur erhalten bleibt.
Außerdem müssen alle für den Stoffwechsel notwendigen Bestandteile vorhanden sein.
Kurz: Alle Makromoleküle, die das Lebewesen für sich selbst und zum Aufbau eines Duplikats benötigt, müssen von selbst und gleichzeitig entstehen. Hardware und Software müssen sozusagen zufällig spontan und zeitgleich entstanden sein. Das so entstandene rudimentäre Lebewesen hätte spontan in der Lage sein müssen, Energie zu gewinnen und sich selbst zu reproduzieren. Keine dieser Voraussetzungen darf fehlen (nicht reduzierbare Komplexität), will man als Ergebnis ein rudimentäres sich selbst reproduzierendes Lebewesen haben. Die Frage, durch was ein Lebewesen „gestartet“ wird, also zu leben beginnt, und woher Enzyme wissen, dass und wie sie interagieren sollen, um komplexe Arbeitsabläufe auszuführen, gibt zu weiterem Klärungsbedarf innerhalb der Evolutionstheorie Anlass.
Wenn die DNS (oder ein anderes informationstragendes Makromolekül) sich nicht bilden kann, würde es zwar nichts nutzen, wenn sich Proteine bilden könnten (so wie Hardware ohne Software völlig sinnlos ist), aber wir wollen auch diesen Fall untersuchen. Es erheben sich daher die Fragen:
- Für DNS: Können die zum Aufbau einer DNS notwendigen Nukleoside unter Laborbedingungen hergestellt werden?
- Können sich individuelle Nukleoside unter Laborbedingungen in Form von Nukleotiden aneinanderketten, so dass das so entstandene Makromolekül am Ende die zum Leben notwendigen Informationen enthält?
- Für Proteine: Können die zum Aufbau von Proteinen notwendigen Aminosäuren unter Laborbedingungen hergestellt werden?
- Können sich individuelle Aminosäuren unter Laborbedingungen aneinanderketten, so dass das so entstandene Makromolekül am Ende ein funktionierendes Protein darstellt?
Das Ergebnis der Miller-Experimente
Das Experiment, das Stanley Miller durchführte, kennen die meisten wahrscheinlich noch aus ihrem Biologiebuch. Bruno Vollmert macht jedoch auf etwas aufmerksam, was nicht im Biologiebuch steht:
Bruno Vollmert: Das Ergebnis dieses für die gesamte Ursuppen- und Selbstorganisations-Diskussion fundamental wichtigen Experiments, das in zahlreichen Laboratorien der ganzen Welt an die hundert Male wiederholt wurde, wird in der Sekundärliteratur leider oft völlig falsch oder unvollständig wiedergegeben. So wurde die irrige Meinung verbreitet, durch den MILLER-Versuch sei experimentell bewiesen, daß sich in der Atmosphäre der frühen Erde Aminosäuren, die Bausteine der Proteine, und Nucleotide, die Bausteine der Nucleinsäuren (DNS, RNS), gebildet haben, aus denen sich unter den Bedingungen der früheren Erde Makromoleküle, wie Nucleinsäuren und Proteine, bilden konnten …
Solchen und ähnlichen euphorischen Fehlinterpretationen dessen, was „Experimente gezeigt haben“, die von Theoretikern stammen, die nach einer experimentellen Basis für ihre sonst im Leeren schwebenden Selbstorganisationshypothesen suchen, stehen die nüchternen Zahlenangaben der Originalliteratur gegenüber, die zwar dem Chemiker zugänglich sind, dem Leser populärwissenschaftlicher Zeitschriften aber leider nicht (Das Molekül und das Leben, p.40,41).
Eine Zusammenfassung der Ergebnisse der Miller-Experimente (und ihrer Varianten) zeigt folgende Tabelle (Wer detailliertere Angaben haben möchte, sei auf K.Dose; H.Rauchfuß; Chemische Evolution und Ursprung lebender Systeme, Wissenschaftliche Verlagsgesellschaft mbH, Stuttgart 1975 verwiesen):
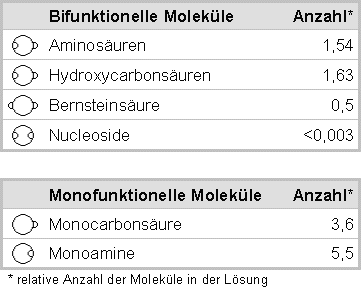
Die Ergebnisse der Miller-Experimente waren für die Hypothesen der Selbstorganisation vernichtend. Die zum Aufbau von DNS notwendigen Nukleoside entstehen überhaupt nicht, bzw. liegen unter der Nachweisbarkeitsgrenze. Wenn aber die Bestandteile der DNS nicht entstehen, wie soll dann eine DNS entstehen?
Was bleibt, sind die Aminosäuren, die allerdings in so geringer Menge entstehen, dass sie sich in Relation zu kettenabschließenden Molekülen nicht durchsetzen können, um lange Molekülketten bilden zu können. Den Einfluss monofunktioneller Moleküle auf das Abbrechen einer Kette bifunktioneller Moleküle beschreibt Bruno Vollmert sehr anschaulich so:
Bruno Vollmert: Makromoleküle sind lange, kettenförmige Gebilde. Sie entstehen im Grunde nicht anders als gewöhnliche Perlenketten oder Gliederketten, nämlich dadurch, daß ein Kettenglied nach dem anderen an die so immer länger werdende Kette angefügt wird. Nur sind Moleküle unsichtbar klein, so daß sie sich selbst mit der feinsten Pinzette nicht fassen lassen. Das ist aber für das Entstehen der langkettigen Makromoleküle auch gar nicht nötig. Wenn man geeignete Moleküle hat, die man als Monomere bezeichnet, fügen sich diese unter dem Einfluß der Molekularbewegung von selbst zur Kette zusammen. Immer dann tun sie das, wenn die verwendeten monomeren Ausgangsmoleküle bifunktionell sind, das heißt sozusagen zwei klebrige Stellen nach Art eines Klettenverschlusses haben, mit denen sie bei passenden Zusammenstößen aneinander hängenbleiben, so daß zwangsläufig lange Ketten entstehen. Voraussetzung für das Funktionieren dieses Mechanismus ist, daß die Monomermoleküle genau zwei Haftstellen haben. Wenn auch Moleküle dabei sind, die nur eine Haftstelle haben und an der anderen Seite glatt sind, besetzen diese sogenannten Monofunktionellen die Kettenenden, und eine Verlängerung der Ketten ist unmöglich, weil zum wiederholten Einhaken von Molekülen notwendigerweise zwei Haftstellen oder Haftgruppen pro Molekül notwendig sind. Als Modell für die Entstehung einer Makromolekülkette stelle man sich einen Kasten mit Kugeln vor, die an zwei gegenüberliegenden Stellen als Haftstellen zwei Druckknöpfe haben, ein Knopfteil und ein Nutteil.
Solange nur solche Kugeln mit je zwei verschiedenen Druckknopfteilen im Kasten sind, kann man beliebig lange eine Kugel nach der anderen aus dem Kasten holen und sie an die immer länger werdende Kette anfügen. Wenn man aber im Vorratskasten bifunktionelle Kugeln (die je zwei Druckknopfteile besitzen) mit monofunktionellen Kugeln (die nur ein Druckknopfteil haben) mischt und mit dieser Mischung eine Kette zu bauen versucht, scheitert das Unternehmen der Kettenbildung sehr bald. Natürlich darf man nur blind in den Kugelkasten greifen, denn Moleküle haben keine Intelligenz und können nicht auswählen, das heißt alle Zusammenstöße geschehen zufällig. Kugeln mit nicht an die Kettenenden passenden Druckknopfteilen gibt man in den Kasten zurück, denn die entsprechenden Zusammenstöße würden bei Molekülen nicht zu einer Verbindung führen. Herausgegriffene Kugeln, deren Druckknöpfe an eine Seite der im Bau befindlichen Kette passen, werden an die Kette angefügt.
Nun kann es sein, daß man Glück hat, indem man zufällig zwei- oder dreimal hintereinander eine bifunktionelle Kugel mit zwei Druckknöpfen zu fassen bekommt, ehe man Kugeln mit nur einem Druckknopfteil greift. Dann entsteht eine Kette mit zwei oder drei oder vier Kugeln pro Kette. Die Wahrscheinlichkeit für das Entstehen von Ketten aus zwei oder drei Kugeln wird aber um so geringer, je größer der Anteil an Kugeln mit nur einem Druckknopfteil in der Ausgangsmischung im Kasten ist. Lange Ketten können sich schon bei geringem Anteil an monofunktionellen Kugeln, das heißt solchen mit nur einem Druckknopfteil, nicht mehr bilden.
Was mit diesem Modellspiel veranschaulicht wird, ist das Gesetz der konstanten Proportionen, auch Stöchiometriegesetz genannt. Dieses Gesetz besagt, daß die Bildung von Makromolekülketten unmöglich ist, wenn sich neben den bifunktionellen größere Anteile an monofunktionellen Molekülen – entsprechend den Kugeln mit nur einem Druckknopfteil – in der Ausgangsmischung befinden, und liefert somit eine klar umrissene naturgesetzliche Bedingung für das Entstehen von Makromolekülen durch Polykondensation.
Monofunktionelle Moleküle (Kugeln mit nur einem Druckknopf) brechen die Kette ab. Lange Ketten entstehen nur, wenn monofunktionelle Moleküle ausgeschlossen sind. Ein Überschuß an Monofunktionellen macht eine Kettenbildung um so unwahrscheinlicher, je größer der Überschuß ist. Das aber bedeutet, daß sich in Ursuppen keine Makromoleküle durch Polykondensation bilden können. (Das Molekül und das Leben, p.54,55)
Wahrscheinlichkeiten
Werden wir konkret: Bifunktionelle Aminosäuren bilden sich unter Laborbedingungen gegenüber monofunktionellen Molekülen im Verhältnis von ungefähr 1 : 6.
Eine Kette ist dann abgeschlossen, wenn sie zwei monofunktionelle Moleküle besitzt (Eins würde den Anfang der Kette bilden, das andere das Ende). Wir müssen also nur berechnen, wie lange es gemäß der Wahrscheinlichkeitsrechnung für Moleküle unterschiedlicher Länge dauert, bis dies der Fall ist. Wir nehmen ein erstes Molekül. Die Chance, dass es sich um eine Aminosäure handelt, beträgt 1:6, d.h. bei sechs Versuchen gelingt es uns einmal. Wir nehmen ein zweites Molekül. Wieder beträgt die Wahrscheinlichkeit, dass es sich dabei um eine Aminosäure handelt 1:6. Die Chance, dass wir zwei Aminosäuren aneinanderketten konnten, beträgt somit 1:36. Die Chance, dass wir eine Kette bestehend aus einer Aminosäure und einem Monofunktioniellem Molekül erhalten, beträgt 5:36. Die Chance, dass zwei Monofunktionelle zusammenhängen, beträgt 25:36 (5:6 · 5:6). Nehmen wir noch ein drittes Molekül, so sehen die Wahrscheinlichkeiten so aus (A = Aminosäure, M = Monofunktionelles Molekül):
A-A-A ( 1:216) M-A-A ( 5:216) M-A-M ( 25:216)
Nun kommt noch ein Molekül dazu:
A-A-A-A ( 1:1296) M-A-A-A ( 5:1296) M-A-A-M ( 25:1296)
Nun kommt noch ein Molekül dazu:
A-A-A-A-A ( 1:7776) M-A-A-A-A ( 5:7776) M-A-A-A-M ( 25:7776)
Das bedeutet, dass die Summe aller 5-kettigen Moleküle 31 aus 7776 beträgt. Wir können also prozentual schreiben: 0,399%. Hier nun die Wahrscheinlichkeiten, für weitere Kettenlängen (Jeweils: Kettenlänge – Entstehungswahrscheinlichkeit in Prozent):
5 - 0,39866255144032921810699588477366%
6 - 0,066443758573388203017832647462277%
7 - 0,011073959762231367169638774577046%
8 - 0,0018456599603718945282731290961744%
9 - 0,00030760999339531575471218818269573%
10 - 0,000051268332232552625785364697115955%
20 - 0,00000000000084788448061528855050077413719622%
50 - 0,000000000000000000000000000000000003835298535...
8307279938498724087815%
100 - 0,000000000000000000000000000000000000000000000...
000000000000000000000000000004745004793208169...
6584780381672384%
Wir wollen eine Aminosäurenkette von 100 Aminosäuren erhalten, damit wir das per Definition kleinstmögliche Protein haben. Wir gehen davon aus, dass sich, wie in obiger Erklärung angenommen, monofunktionelle und bifunktionelle Moleküle statistisch in gleicher Häufigkeit aneinanderketten und können so sehr einfach die Wahrscheinlichkeit errechnen, dass sich in der im Miller-Experiment simulierten Ursuppe ein Protein bestehend aus 100 Aminosäuren zufällig durch Polykondensation bildet (Zu etwaigen Einwänden gegen diese Annahmen siehe Anmerkung 1). Wie sieht das Ergebnis aus? Damit sich eine einzige Kette aus 100 Aminosäuren bildet, benötigt man 2,11 · 1076 Moleküle. So viele Moleküle kann es aber im ganzen Universum nicht geben, selbst wenn alle Materie im Universum aus Ursuppe bestehen würde, die aus nichts anderen mehr bestehen würde als aus Molekülen. Im Prinzip gilt das auch für jedes andere denkbare Makromolekül, da die Gesetze der Polykondensation auf alle Makromoleküle Anwendung finden.
Selbst wenn sich jede Sekunde so viele Moleküle zusammenketten, wie es Wassermoleküle in den Weltmeeren gibt (das sind rund 4,65 · 1046, siehe Anmerkung 2), müssten über 3 Billion Erdzeitalter vergehen (angesetzt mit 4,5 Mrd Jahren), bis sich auch nur eine solche Sequenz einmal bilden würde, die dann natürlich keine sinnvolle Funktion, sondern eine zufällige (chaotische) Abfolge von Aminosäuren aufweist. Zum Leben benötigt man aber wesentlich mehr als nur irgendein (funktionsloses) Protein in Minimalgröße. Eine solche Aminosäurekette wäre, selbst wenn sie eine Funktion besäße, völlig nutzlos, da Enzyme ohne Lebewesen so überflüssig sind wie ein Lexikon auf CD-ROM im Mittelalter. Solange kein Lebewesen da ist, das ein Enzym zum Leben benötigt, benötigt man auch kein Enzym. Außerdem wäre ein solches Enzym dem Zerfall ausgesetzt.
Fazit:
Ein Lebewesen benötigt eine DNS (oder ein vergleichbares Makromolekül) und zur Aufrechterhaltung des Lebens (Stoffwechsel, Reproduktion) verschiedene Enzyme. Ein Makromolekül wie die DNS kann jedoch nicht von selbst entstehen, da die dazu notwendigen Einzelmoleküle entweder gar nicht zufällig entstehen oder aber nur zusammen mit monofunktionellen Molekülen, die eine Molekülkette abbrechen. (Bei DNS: Nukleoside + Phosphorsäure verbinden sich zu Nukleotiden + Estergruppe zu einer DNS-Kette). Enzyme bilden sich aufgrund der viel zu geringen Wahrscheinlichkeit der Aneinanderkettung von Aminosäuren nicht (zumindest nicht in den für das Erdzeitalter relevanten Zeiträumen). Mit den kettenbildenden Molekülen (Aminosäuren und Hydroxycarbonsäuren) bilden sich immer (!) auch kettenabbrechende Moleküle (Monokarbonsäuren und Monoamine), diese selbst unter Laborbedingungen in wesentlich größerer Menge. Es ist daher müßig, darüber nachzudenken, ob ein Makromolekül, das niemals von selbst entstehen kann, Informationen enthält oder nicht. Genauso wenig macht es Sinn, die Frage zu stellen, ob die Proteine, die niemals zufällig entstehen können, Funktionen besitzen.
Der Einwand, es könnten sich doch auch andere Makromoleküle von selbst gebildet haben, die die Funktionen der heute existierenden ersetzen konnten, steht vor dem gleichen Grundproblem der Polykondensationsgesetze. Diese treffen auf alle Makromoleküle zu, nicht nur auf das Makromolekül DNS. Da das DNS-Molekül jedoch der einzige Träger der Erbinformationen in Lebewesen ist, müsste er ja irgendwie entstanden sein. Der direkte Weg ist nur durch Einsatz von Intelligenz möglich. Wie sich DNS durch Umgehung grundlegender Naturgesetze von selbst gebildet haben könnte, ist unbekannt. Unkenntnis ist stets eine schwache Argumentationsgrundlage. Auf dieser Grundlage das Gedankenmodell der Evolution aufzubauen und zu behaupten, nur Dummköpfe würden sich dieser Theorie versagen, während gleichzeitig versucht wird, diese Theorie gegen jeden Angriff durch Unkenntnis der Mechanismen zu immunisieren, ist einmalig in der Wissenschaft.
Die Frage, wie in ein solches von selbst entstandenes Makromolekül durch Zufall sinnvolle Informationen codiert werden konnten, ist ebenfalls völlig unbekannt. Das scheint aber Evolutionsbefürworter überhaupt nicht zu stören. Sie verweisen auf zukünftige Entdeckungen, die Licht ins Dunkel bringen sollen. Und wenn man auch zukünftig nichts entdeckt, dann ist das auch nicht schlimm. Dann bleibt die Evolutionstheorie eben ein „ewiges Geheimnis“, was wohl eher an theologische Begrifflichkeiten erinnert. So eine Herangehensweise ist aber eher untypisch für echte Wissenschaft.
Die Evolutionstheorie ist sowohl was die Abiogenese- als auch die Deszendenz-Theorie angeht, ein äußerst unbefriedigendes Erklärungsmodell, da man nicht nur die Mechanismen nicht kennt, mit denen die Entstehung des Lebens abgelaufen sein soll, sondern im Gegenteil die Mechanismen kennt, die eine Evolution unmöglich machen.
Bruno Vollmert: Was ich aber weiß, ist, daß die modernen Hypothesen über die Entstehung des Lebens durch Selbstorganisation und die Entstehung der Arten durch Mutation-Selektion sich auf exakt-naturwissenschaftlich überprüfbare Aussagen berufen und daß diese es sind, die mit den experimentell gesicherten Erkenntnissen der Makromolekularen Chemie (genauer: den stöchiometrischen, thermodynamischen und statistischen Gesetzen der Synthesereaktion von langkettigen Molekülen) im Widerspruch stehen und so als widerlegt gelten müssen. (Das Molekül und das Leben, p.22,23)
Anmerkung 1: Treffen die Polykondensationsgesetze auf die Entstehung des Lebens zu?
Dieser Frage geht Bruno Vollmert ebenfalls nach. Hier seine Antwort:
Bruno Vollmert: Sind die Aussagen, die sich aus den Polykondensationsgesetzen herleiten, einerseits und die Aussagen über die Rahmenbedingungen der frühen Erde andererseits so sicher, daß die verneinende Antwort auf die Frage nach der Entstehung des Lebens durch Selbstorganisation zwingend ist?
Was die stöchiometrischen Polykondensationsgesetze betrifft, so gehören diese zu den fundamentalen Aussagen, die sich unmittelbar von der atomaren Struktur der Materie herleiten, das heißt, die atomare Struktur der Materie läßt eine andere Aussage über die Abhängigkeit der Kettenlänge vom Bi-: Mono-Verhältnis als die der Stöchiometriegleichung (siehe Seite 57) nicht zu: Bei großem Überschuß an monofunktionellen Stoffen mit gleicher Reaktionsgeschwindigkeit ist die Entstehung von Makromolekülen durch Polykondensation extrem unwahrscheinlich, um so unwahrscheinlicher, je höher das Molekulargewicht ist.
Anders möchte man (zumindest auf den ersten Blick) die Aussagen über die Zusammensetzung von Uratmosphäre und Ursuppe bewerten, denn der Zustand der Erdoberfläche vor vier bis fünf Milliarden Jahren ist unserer direkten Beobachtung entzogen. Speziell die Zusammensetzung der Uratmosphäre ist umstritten und wird dies wohl auch in Zukunft bleiben.
Trotzdem wäre es falsch; nun pauschal von „uns nicht bekannten historischen Rahmenbedingungen“ zu sprechen und so zu tun, als wüßten wir von der frühen Erde gar nichts. Die Zusammensetzung der Uratmosphäre mag im Detail gewesen sein, wie sie will, sie war mit Sicherheit einer starken UV-Strahlung, dem Sonnenwind (mit wechselnder Stärke, je nach Stärke des erdmagnetischen Feldes) und der kosmischen Strahlung ausgesetzt, so daß sich kleine organische Moleküle bilden konnten. Formaldehyd (CH2O), aus dem sich Ribose und andere Zucker bilden können, und Blausäure (HCN), die als Ausgangsmaterial für die vier in den Nucleinsäuren mit Ribose verbundenen Basen in Betracht kommt, sind im interstellaren Gas nachgewiesen, zahlreiche Aminosäuren wurden in Meteoriten gefunden, so daß die Annahme einer Uratmosphäre, die bei Energiezufuhr (Strahlung, Hitze, Blitze) Aminosäuren bildet, nicht unbegründet ist.
Ganz sicher aber ist, daß da, wo sich Aminosäuren bilden konnten, immer auch monofunktionelle Stoffe wie Ameisensäure, Essigsäure und Amine entstehen mußten. Das ergibt sich zwingend aus den MILLER-Versuchen (siehe Seite 42), die ja nun wirklich oft genug in den verschiedensten Laboratorien immer mit dem gleichen Resultat wiederholt worden sind.
Die in der neueren Literatur zu findende Annahme, daß die richtigen Monomeren, die Nucleotide oder Aminosäuren, schneller reagierten, ist durch nichts zu begründen. Im Gegenteil haben Experimente gezeigt, daß zum Beispiel Nucleosidphosphate fünfzigmal rascher mit NH2-Gruppen (die sich auch in Aminosäuremolekülen befinden) reagieren als mit den OH-Gruppen der Ribose, mit denen sie eigentlich reagieren müßten, um RNS zu bilden. Im allgemeinen gilt: Wie auch immer die richtigen Monomeren unter günstigen Bedingungen aktiviert werden, die monofunktionellen Kettenabbrechermoleküle sind mit von der Partie. Nur Enzyme, die hochspezifischen Biokatalysatoren, sind in der Lage, bestimmte Moleküle auszuwählen und zu begünstigen. Enzyme aber gab es in der Ursuppe nicht, denn Enzyme sind Proteine mit hohen Molekulargewichten. (Das Molekül und das Leben, p.63-65).
Es gibt noch etliche andere Gründe, warum sich Makromoleküle nicht von selbst bilden können. Einzelheiten findet der Leser in Bruno Vollmerts Buch Das Molekül und das Leben – Vom makromolekularen Ursprung des Lebens und der Arten: Was Darwin nicht wissen konnte und Darwinisten nicht wissen wollen.
Anmerkung 2: Anzahl Wassermoleküle in den Weltmeeren
Ein Wassermolekül besteht aus einem Sauerstoffatom (8 Protonen, 8 Neutronen, 8 Elektronen) und zwei Wasserstoffatomen (insgesamt 2 Protonen und 2 Elektronen). Das Gewicht eines Protons beträgt 1,6726231 · 10-27kg. Das eines Neutrons 1,6749286 · 10-27kg und das eines Elektrons 9,1093897 · 10-31kg. Wenn wir für unsere Berechnungen (mit ohnehin gerundeten Zahlen) davon ausgehen, dass ein Wassermolekül die gleiche Masse hat, wie die Summe der Ruhemassen seiner Bestandteile, so kommen wir auf ein Gewicht für ein H2O-Molekül von 3,01347691897 · 10-26kg.
Wenn wir bei dem Meerwasser die Verunreinigungen und Halogene vernachlässigen und von völlig reinem H2O ausgehen, so kommen wir bei einem Liter Wasser auf eine Molekülmenge von 33.184.259.474.660.183.313.731.830 einzelnen H2O-Molekülen.
Die Masse des Wassers der Ozeane wird mit 1,4 · 1021kg angegeben. Die Ozeane enthalten somit rund 4,65 · 1046 Wassermoleküle.
Anmerkung 3: Grundsätzliches zur Protein-Codierung in der DNS
Die folgenden Ausführungen sind nur als Hintergrundinformation gedacht:
Die DNS ist zu einer Doppelhelix geformt. Dieser Strang wird bei Kopiervorgängen kurzfristig aufgetrennt, um eine RNS-Matrix zu erstellen.
Die DNS besteht aus folgenden Nukleotiden:
- (A) Adenin
- (G) Guanin
- (C) Cytosin
- (T) Thymin
Dabei gehören A und T zusammen, sowie G und C. Die Anzahl aller möglichen Kombinationen beträgt 4 (A-T, T-A, G-C und C-G). Mit den vier Buchstaben lassen sich somit 4 Werte darstellen (entspricht 2 Bit). Drei dieser Kombinationen (Triplett genannt) ergeben ein ‚Wort‘. Die Anzahl der dadurch möglichen unterschiedlichen Worte beträgt 64 (4 x 4 x 4 = 64, das entspricht 6 Bit). Es stehen somit 64 mögliche ‚Worte‘ zur Verfügung. Da aber nur 20 verschiedene Aminosäuren verwendet werden, stehen für eine Aminosäure meist mehrere Tripletts zur Verfügung.
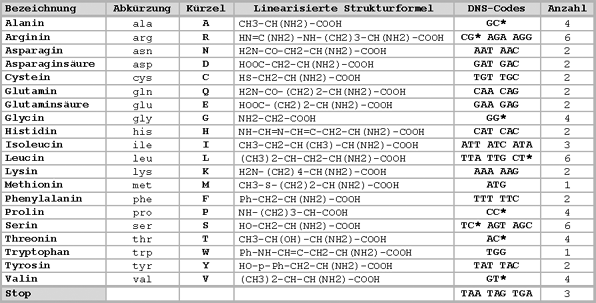
Da 4 x 4 aber nur 16 ergibt, würde ein ‚Wort‘ aus zwei Kombinationen nicht ausreichen, um 20 Aminosäuren zu codieren.
Jede Aminosäure lässt sich also mit unterschiedlich vielen Triplets codieren. Manche Aminosäuren lassen sich nur mit einem Triplet codieren (Methionin und Tryptophan), andere lassen sich mit 6 verschiedenen Triplets codieren (Arginin, Leucin und Serin).